

技术分享

从“能聊天”,到“能干活”
最近,越来越多团队开始部署 AI Agent(智能助手),不再满足于“问一句答一句”的ChatGPT模式,而是让AI真正“动手”——执行命令、读写文件、操作浏览器、定时巡检。
这类工具的代表之一是 OpenClaw,一个开源的AI Agent平台。它可以部署在服务器上,通过Telegram、钉钉、企业微信等渠道接入,让AI像一个真正的员工一样工作。

但问题来了:一个能操作你服务器的AI,如果被别人连上了呢?
我们在实际部署和安全评估中发现,相当数量的OpenClaw网关(Gateway)直接暴露在互联网上,常见端口包括 3001 、 18789 等。
这意味着什么?
意味着任何人都可以尝试连接你的AI助手的“大脑中枢”。
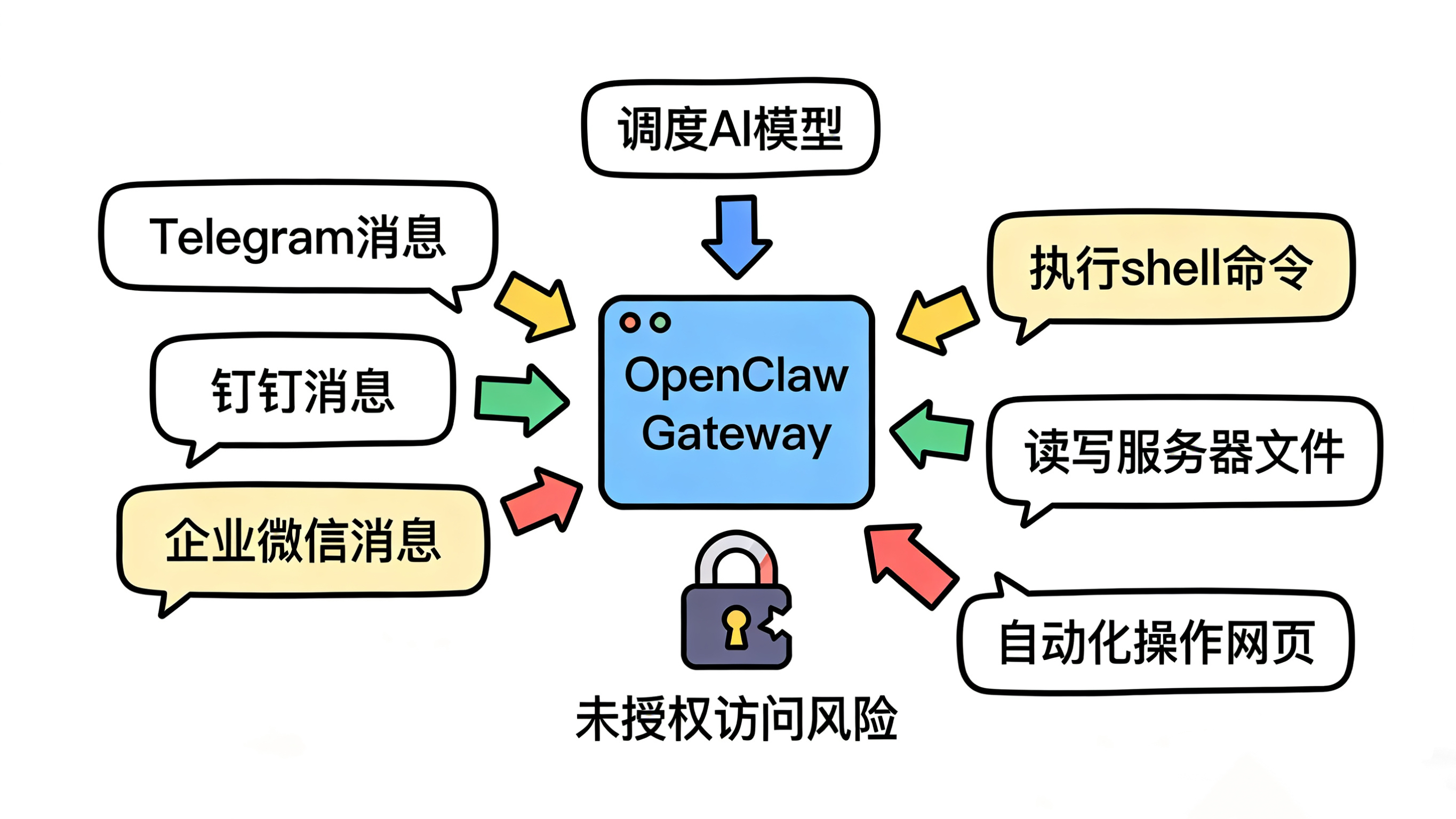
OpenClaw的架构中,Gateway(⽹关)是整个系统的核⼼:
接收消息:来⾃Telegram、钉钉、企业微信的所有对话
调度AI:决定⽤哪个模型、执⾏哪些⼯具
执⾏命令:通过exec⼯具直接在服务器上跑shell命令
读写⽂件:访问服务器上的⽂件系统
控制浏览器:⾃动化操作⽹⻚
⽹关 = AI助⼿的⼤脑 + 双⼿ + 眼睛。
⼀旦⽹关被未授权访问,攻击者等于接管了这个AI能做的⼀切。
三种真实的攻击场景
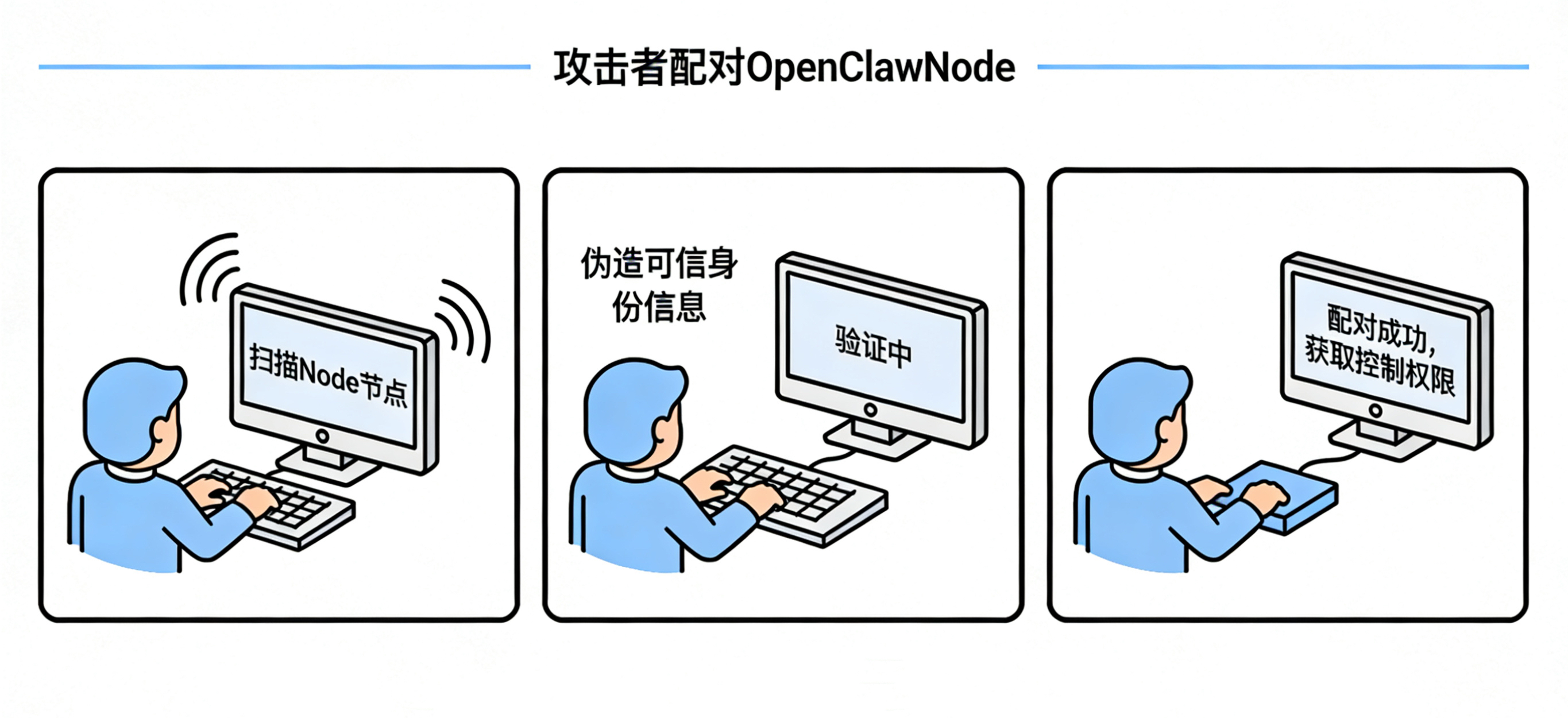
OpenClaw⽀持"Node"机制——让⼿机、其他电脑配对连接到⽹关。如果⽹关暴露在公⽹且认证较弱,攻击者可以:
1. 扫描发现你的⽹关端⼝
2. 尝试⽤常⻅token或默认配置连接
3. 成功配对后,以Node身份执⾏命令
后果: 攻击者获得服务器shell权限。
⽹关提供WebSocket接⼝⽤于Control UI和客户端通信。如果:
gateway.auth.tokens设置了弱密码
或配置了allowInsecureAuth:true
攻击者可以直接通过WebSocket连接⽹关API,发送指令让AI执⾏任意命令。
后果: 远程代码执⾏(RCE),和SSH被⼊侵⽆异。
如果AI Agent接⼊了群聊(如Telegram群、微信群),任何群成员都可以通过对话引导AI执⾏操作——这不是漏洞,是设计上的信任模型:
OpenClaw假设同⼀个⽹关下的所有⽤户处于同⼀信任域。
后果: 群⾥任何⼈都能间接调⽤AI的所有⼯具权限。

一个危险的配置组合
我们⻅过最危险的实际配置:

这等于:在互联⽹上开了⼀个⽆密码的SSH,⽽且还有AI帮你⾃动执⾏命令。
第⼀步:检查端⼝暴露
检查服务器是否对外直接暴露了3001、18789等OpenClaw默认端口且未设置访问控制策略,如果端口开放,服务器的网关可能是裸奔状态。
第⼆步:检查关键配置
登录服务器,查看OpenClaw配置⽂件
(通常在~/.openclaw/openclaw.json):
 第三步:运⾏官⽅安全审计
第三步:运⾏官⽅安全审计
 这个命令会⾃动检查常⻅的安全配置问题。
这个命令会⾃动检查常⻅的安全配置问题。

加固建议
一、⽹络层:不要直接暴露
最佳⽅案: 使⽤ Tailscale / WireGuard 组建私有⽹络,⽹关只监听内⽹。
次选⽅案: 如果必须公⽹访问,前⾯加 Nginx 反向代理+ HTTPS + IP⽩名单。

二、认证层:强Token + 关闭不安全认证

三、权限层:最⼩化exec权限

只允许⽩名单⾥的命令执⾏,未知命令需要⼈⼯审批。
四、信任层:分离信任域
个⼈助⼿和团队助手⽤不同的⽹关实例
不要让⼀个Agent同时接⼊私⼈渠道和公开群聊
敏感操作的Agent单独部署
四、实操层:运行安全检查Skill
针对前文提到的网关暴露、认证薄弱、执行权限过大等问题,矢安科技知深攻防实验室基于此,撰写示例Skill,适用场景:
定期安全巡检
部署前安全加固
发现潜在配置风险
建议优先采用以下两种方式进行审计:
方式一:基于示例Skill自行复制、编写
为 OpenClaw 单独添加一个安全审计 Skill,用于自动检查配置文件中的安全风险,并执行安全审计。
Skill 定位:OpenClaw网关安全自动化审计与配置检查工具,自动检查 OpenClaw 配置文件中的常见安全风险,执行安全审计。
SKILL.md及scripts下载地址:
https://github.com/ASantsSec/OpenClaw-Security-Audit
接入后,可以将其作为日常巡检工具使用,在每次部署、变更配置或例行检查时执行一次审计,以便尽早发现高风险配置。
方式二:从ClawHub获取插件
如果您希望更快落地,也可以直接前往ClawHub下载本团队撰写的示例插件。
插件名称:
openclaw-security-policy-check
下载地址:
https://clawhub.ai/ASantsSec/openclaw-security-policy-check
这种方式更适合希望快速完成检查、减少手动接入成本的场景。安装后可直接用于策略检查与配置核验。
AI Agent正在从"能聊天"进化到"能⼲活",这是巨⼤的效率提升。但能⼒越⼤,⻛险越⼤。
⼀个部署在服务器上、能执⾏命令的AI Agent,本质上就是⼀个⾃动化的运维通道。它的安全级别,应该等同于你对SSH、远程桌⾯的安全要求。
不要让你的AI助⼿,成为攻击者最喜欢的⼊⼝。

